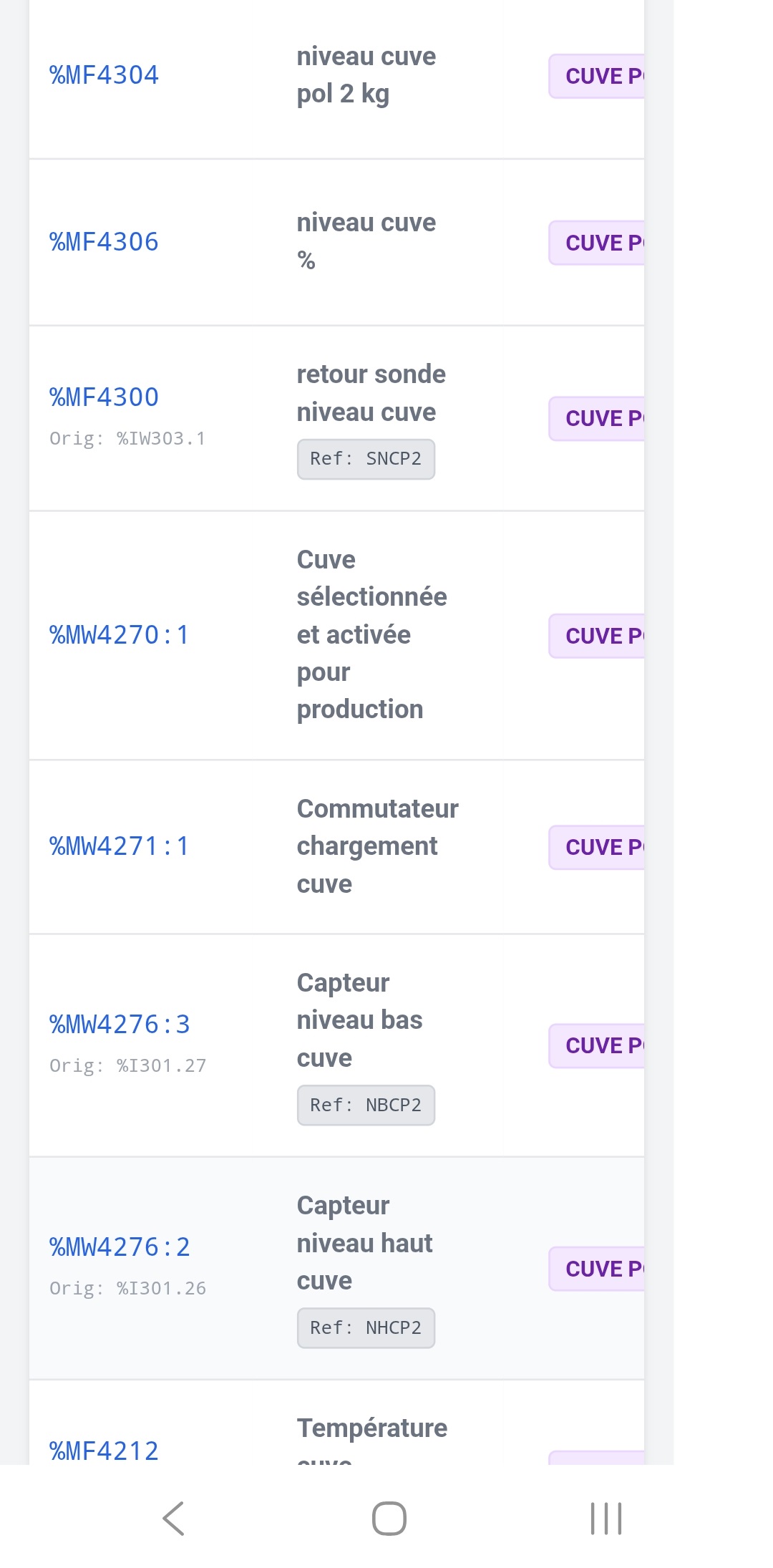
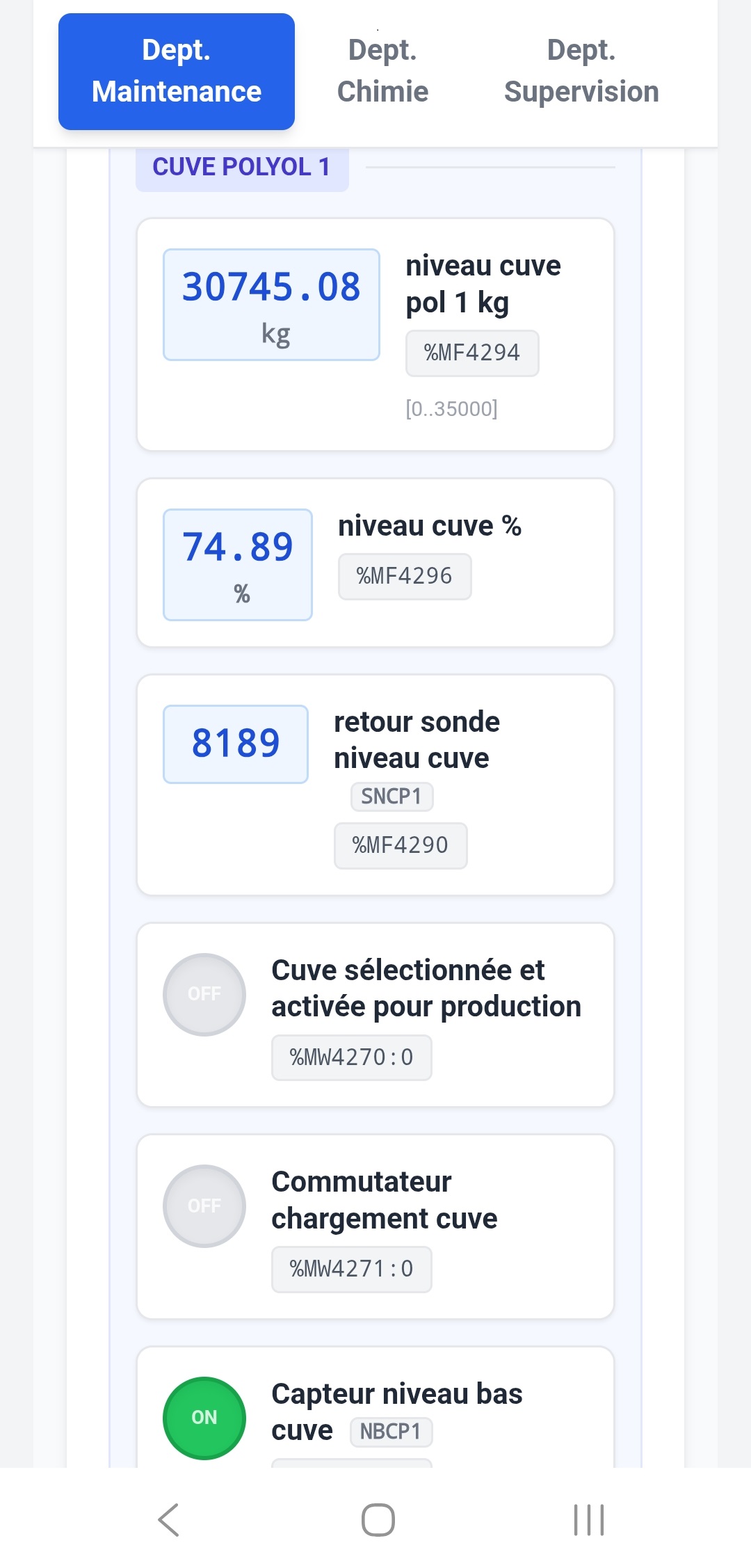
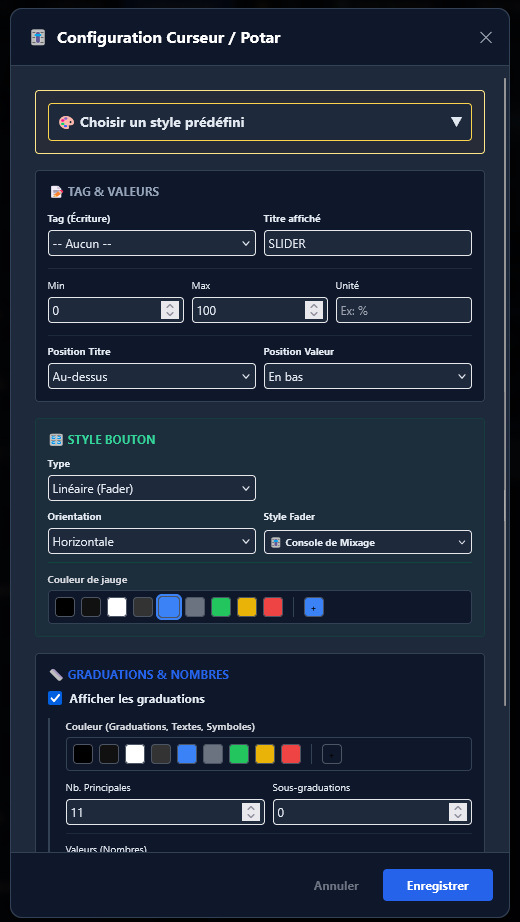
Le contexte
Cela fait cinq ans que dans l'usine où je travaille, les ordres de commandes sont transmis à la ligne de production par saisie manuelle des opérateurs. Cinq ans d'erreurs de saisie possibles, de produits non conformes, de frictions quotidiennes que tout le monde a fini par accepter comme une fatalité. Sans compter les lenteurs qui s'étaient glissées progressivement dans nos systèmes de supervision suite à l'accumulation de mises à jour et à l'ajout de fonctionnalités et d'outils de production, les valeurs tardaient à se rafraîchir.
Automaticien et technicien de maintenance depuis plus de vingt ans, je suis par nature à la recherche de solutions concrètes. Avant de me lancer seul, j'avais pourtant essayé la voie officielle : la maison mère dispose d'une équipe d'ingénieurs spécialisés dans ce type de sujets. Nous avons eu un contact direct avec eux, partagé toutes les données, les programmes, les spécifications. Un an plus tard ... rien. Probablement une question de priorités, de rotation du personnel, ou simplement le fait qu'ils travaillent principalement sur des environnements Siemens récents plutôt que sur des installations Schneider vieillissantes qui n'étaient pas vraiment dans leurs habitudes ... ou alors à la recherche d'une vision plus globale de remplacement des automates et des supervisions sans que l'on sache vraiment où cela en est. J'ai donc décidé de m'atteler moi-même au problème.
Il me fallait pour ça deux choses :
Les fichiers contenant les ordres de production sont exportés automatiquement sur un serveur sous forme de fichiers textes.
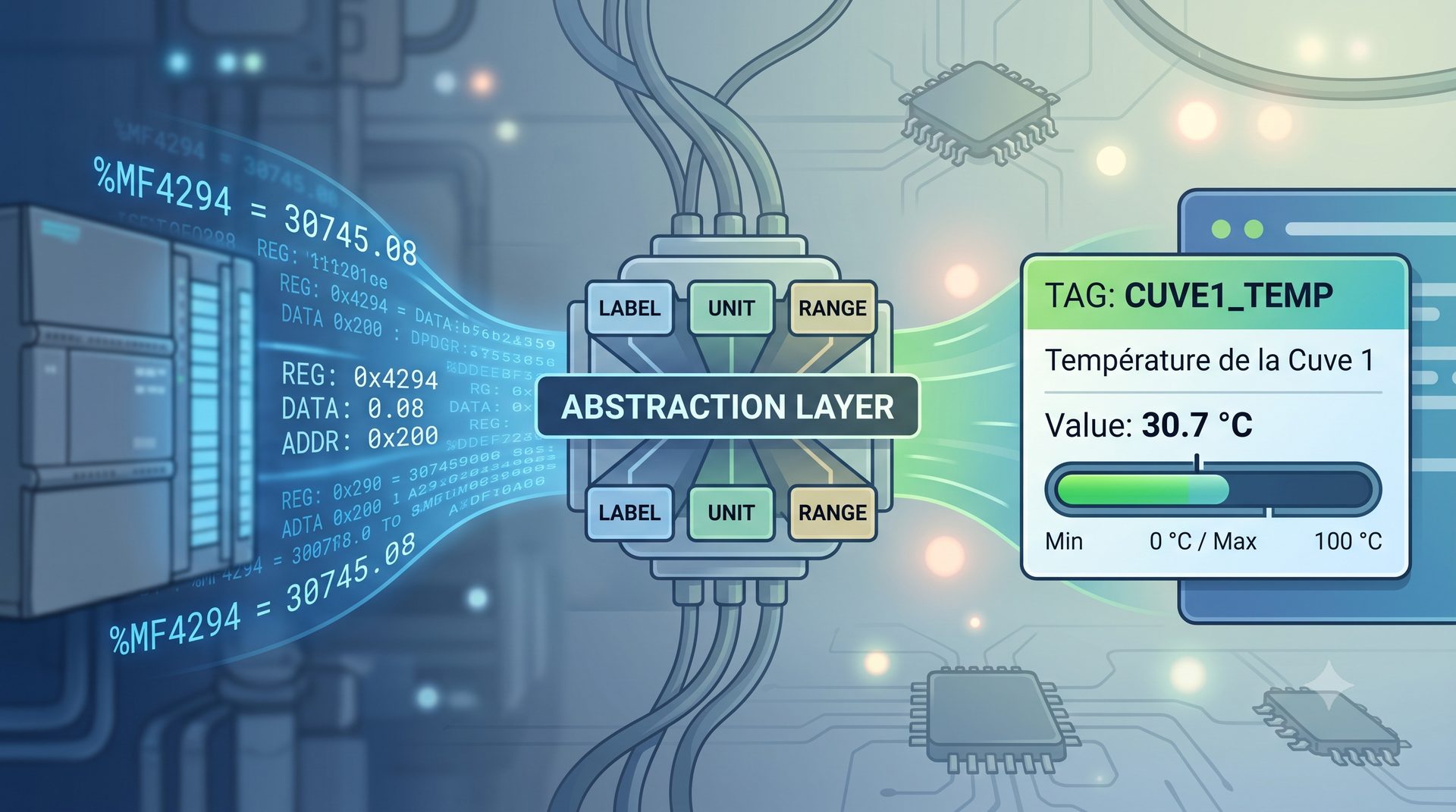
Parser texte · terrain connuTransférer ces données formatées vers le poste de supervision, qui communique avec un automate Schneider.
Communication PC <> automate Schneider Premium · terrain inconnuPlutôt que de passer par l'approche classique dans l'industrie pour ce type d'application: un programme compilé en Delphi ou en C++ interfacé avec l'automate, je me suis demandé si je ne pouvais pas utiliser des outils plus ouverts et modernes : Node.js côté serveur, React côté interface, comme il s'agit d'outils tendances que j'avais commencé à utiliser l'année précédente pour un projet personnel d'application de gestion de la maintenance.
La motivation : résoudre un problème concret, et découvrir qu'il y avait quelque chose de plus grand à construire
Deux heures de recherche plus tard, ce que je croyais devoir me prendre deux semaines s'est résumé à un constat : "Mais c'est juste ça ?" Depuis mon ordinateur personnel, avec une petite interface rudimentaire, je pouvais lire et écrire directement des mots mémoire %MWxxxx sur un automate Schneider Premium. Et là, tout s'est enchaîné très vite dans ma tête.
"Et pourquoi pas ?", Si je peux parler à un automate depuis mon PC en quelques heures, qu'est-ce que je peux construire avec quelques semaines de travail ?
J'avais maintenant la conviction que je pouvais faire quelque chose de plus grand. Pas seulement résoudre ce problème de saisie, mais m'attaquer à une frustration que je traîne depuis des années dans mon métier : les outils de supervision industriels coûtent une fortune, tournent sur des plateformes propriétaires verrouillées, dès que nous devons remplacer un PC avec une version supérieure de l'environnement système alors il faut migrer vers une nouvelle version du logiciel HMI avec des licences à mettre à jour, des heures de migration du programme de supervision à prévoir, des outils de licence nécessitant autant de formation que pour l'utilisation du logiciel lui-même, et dès qu'on veut personnaliser quelque chose au-delà de ce que l'éditeur a prévu, c'est soit impossible, soit une semaine de développement dans un langage des années 90. J'ai utilisé WinCC, InTouch, des outils solides, mais fermés, et souvent inaccessibles pour les petites structures à cause de leur coûts.
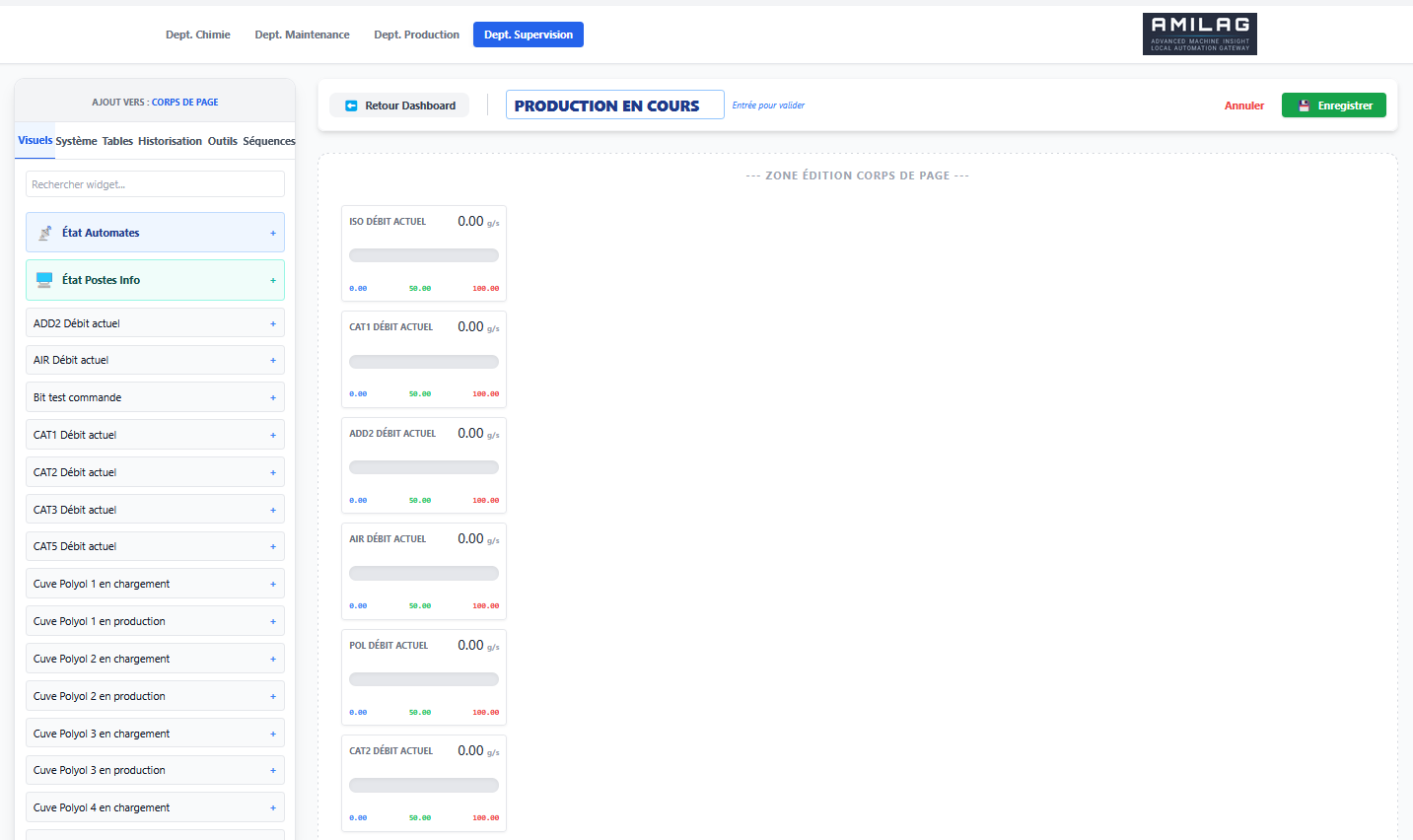
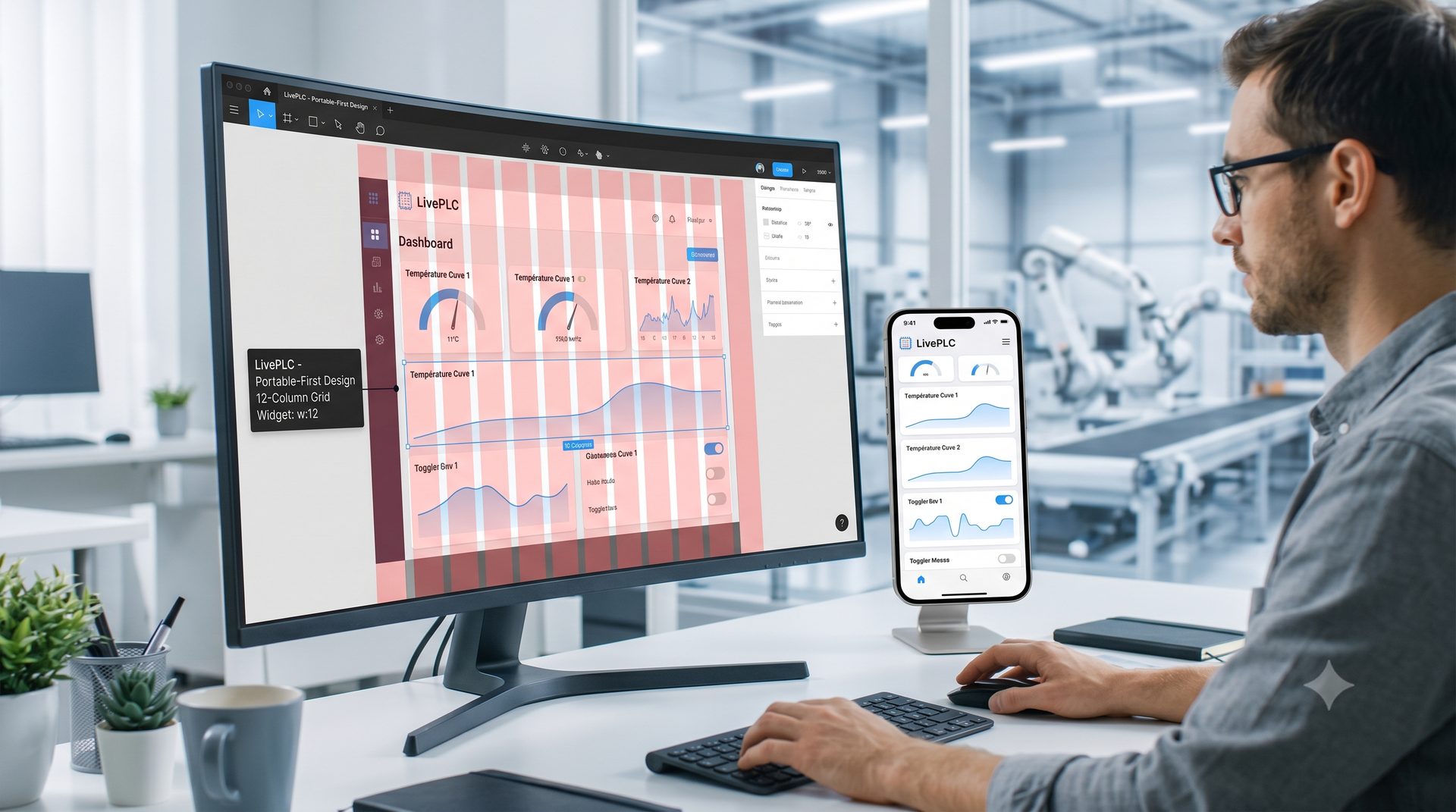
L'idée s'est imposée : et si je construisais une interface de supervision aussi flexible qu'un site web, connectée directement aux automates, et accessible depuis n'importe quel écran, y compris le smartphone qu'on a dans la poche en atelier ? En cas de remplacement d'un poste, plus besoin de migrer, plus besoin de tout réinstaller pendant des heures par un ingénieur système. Là avec ce système : un navigateur et une adresse web locale, et c'est reparti !
La vision et le plan d'action

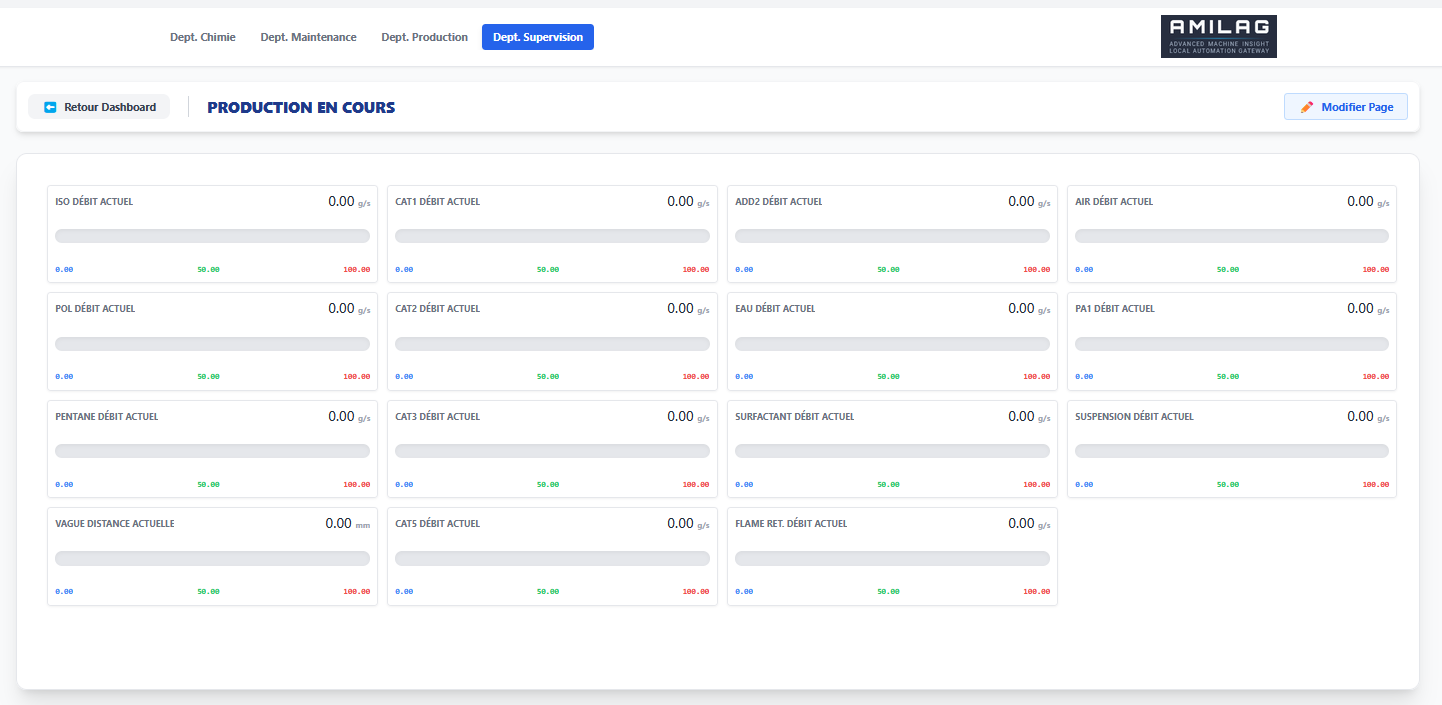
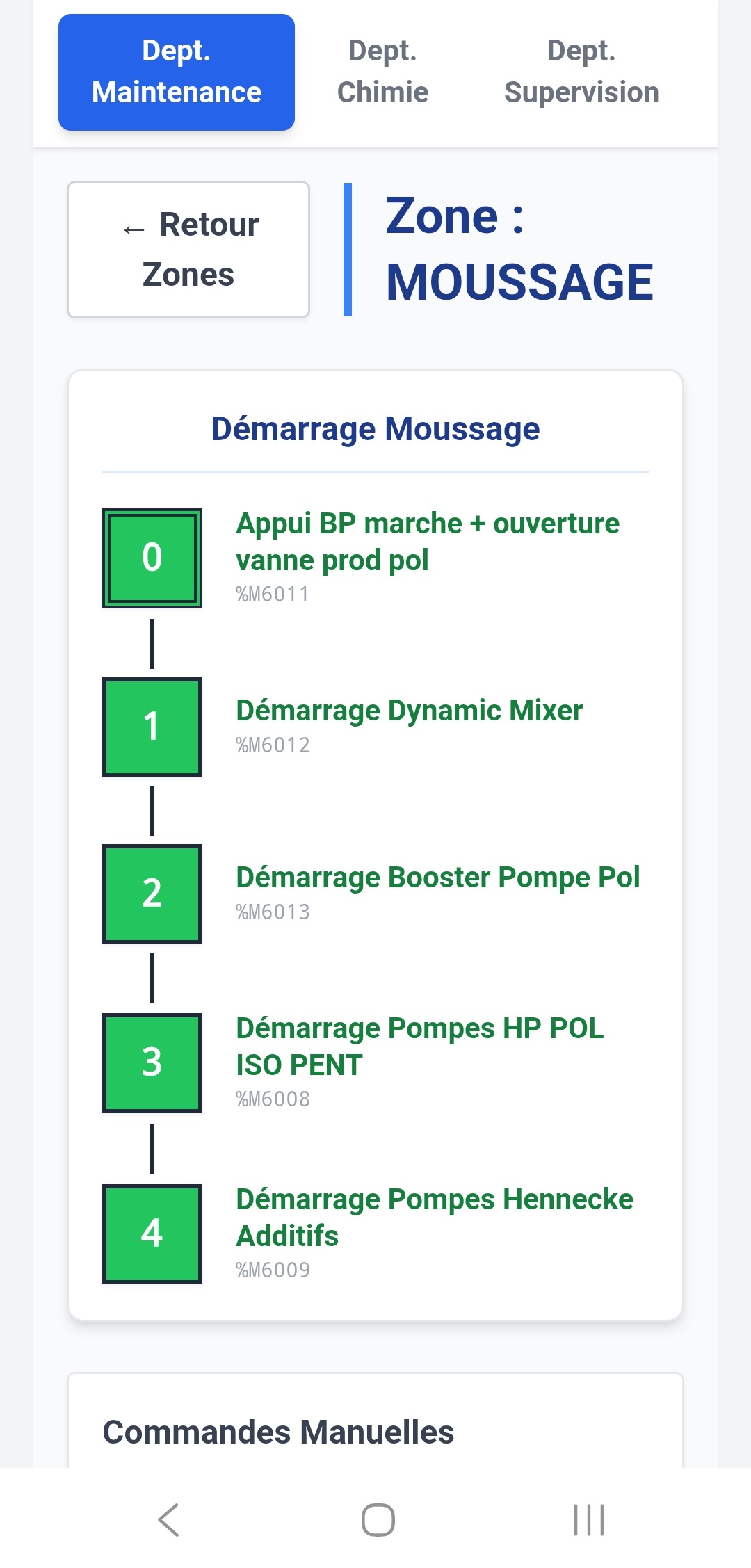
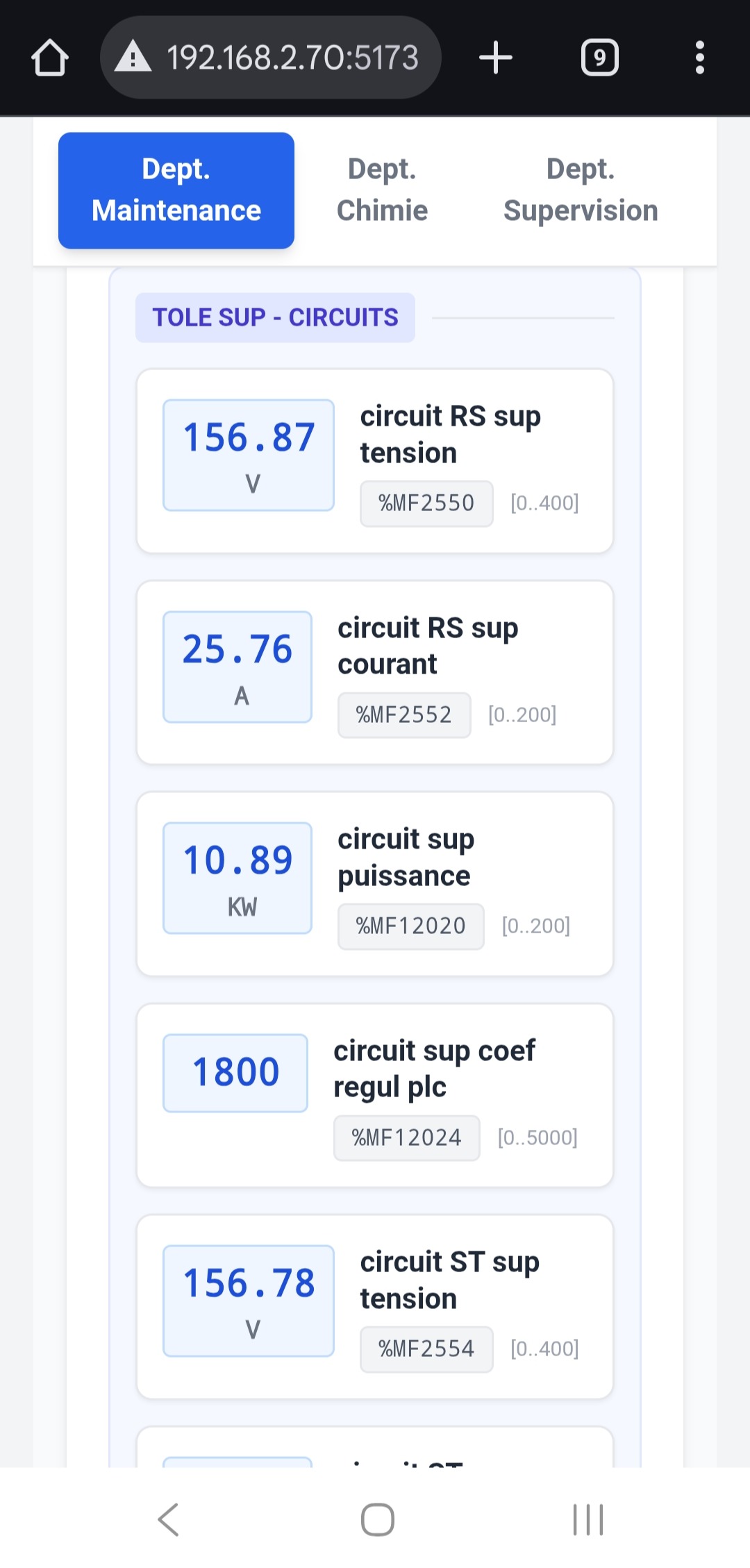
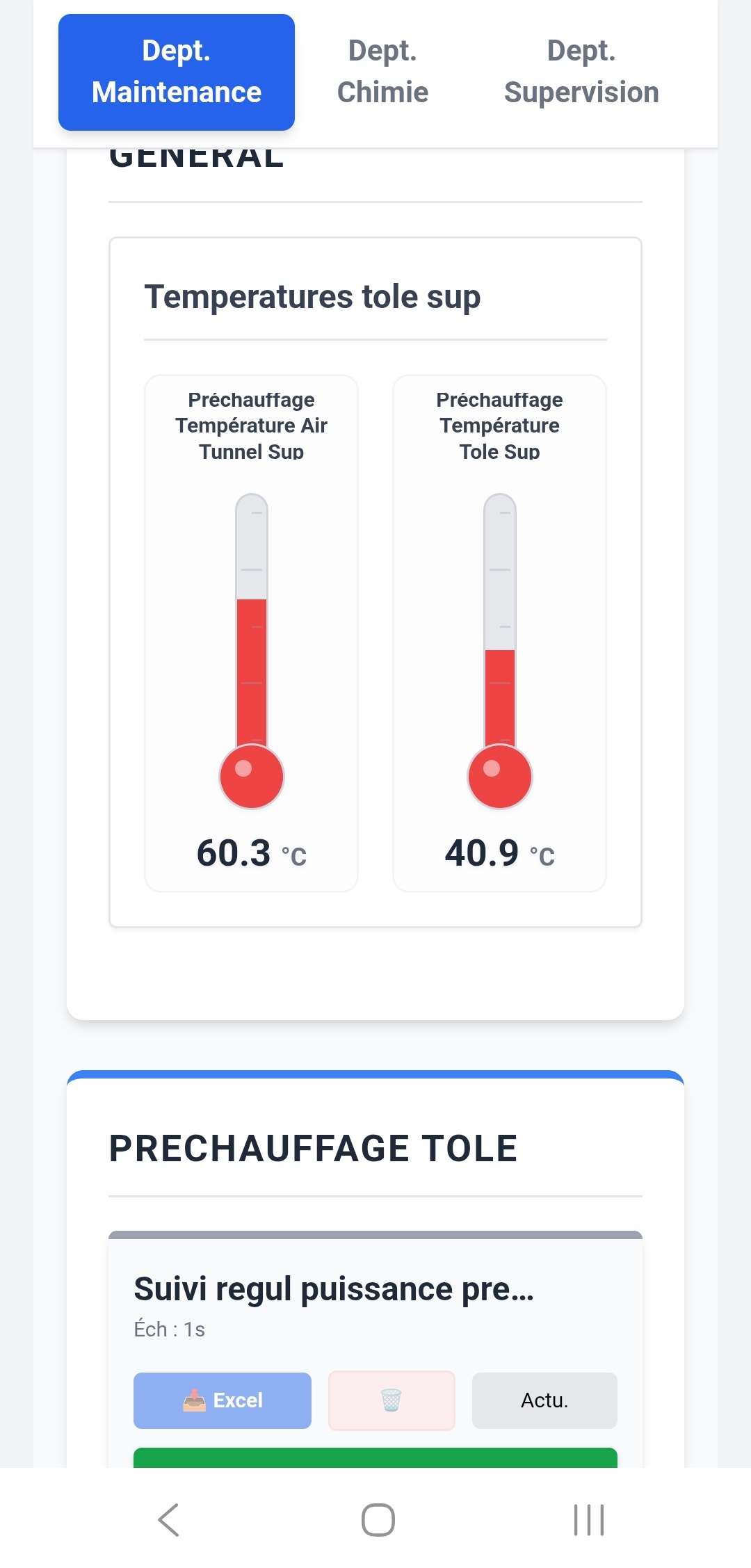
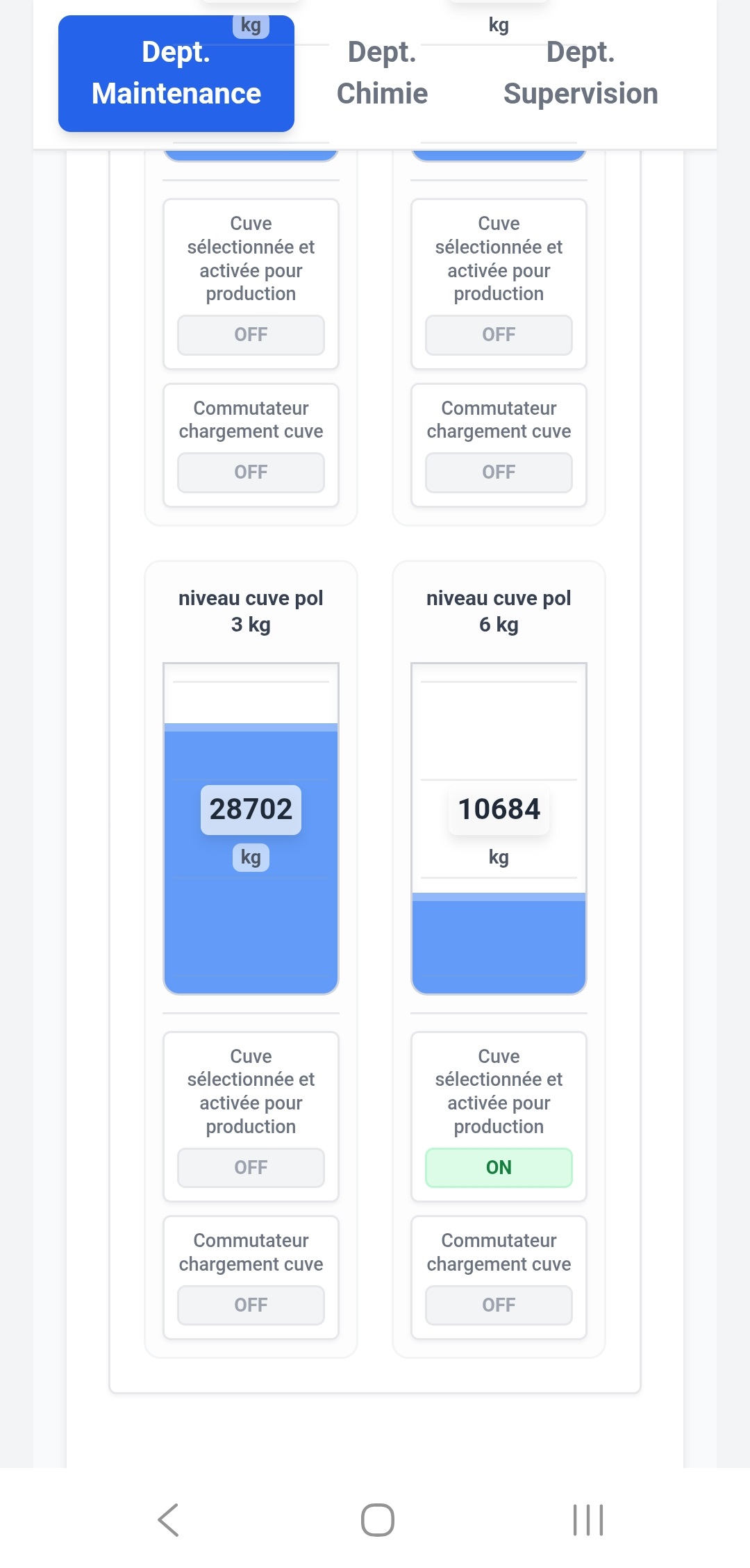
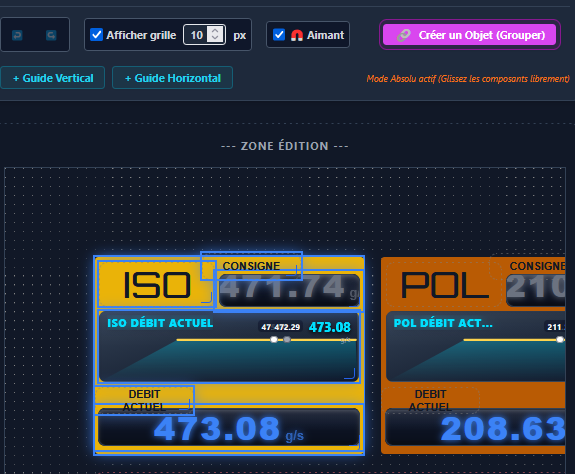
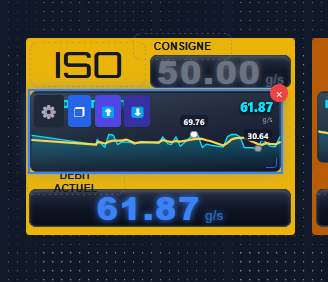
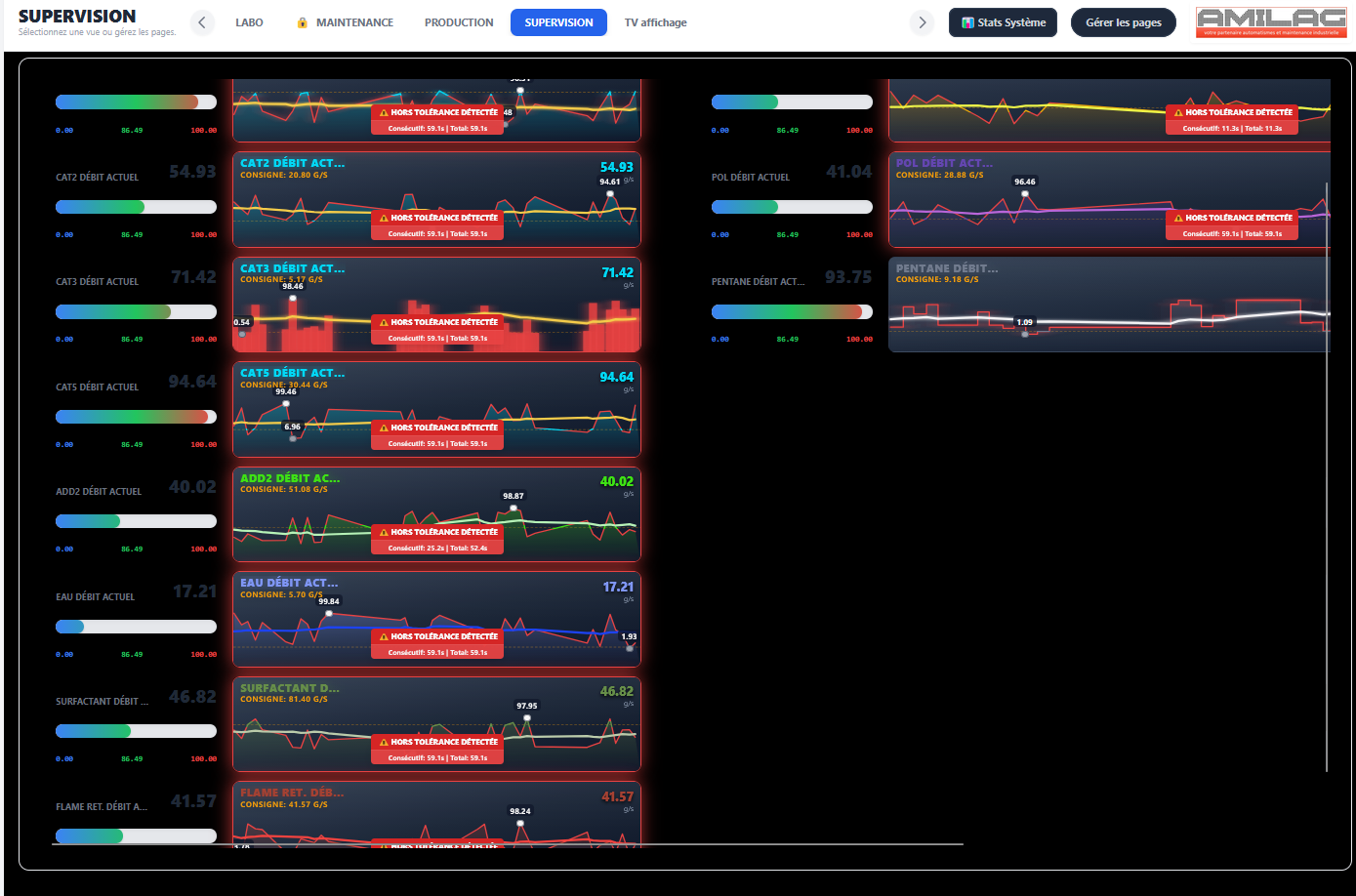
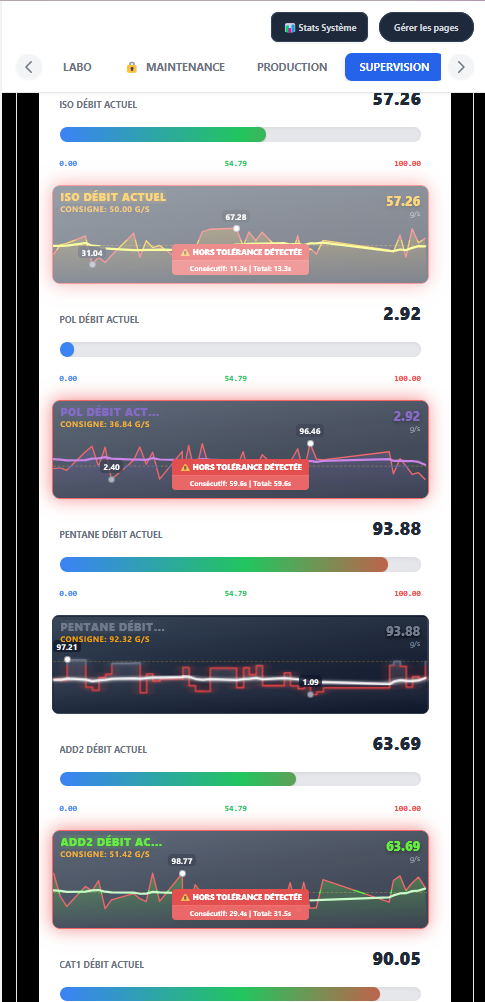
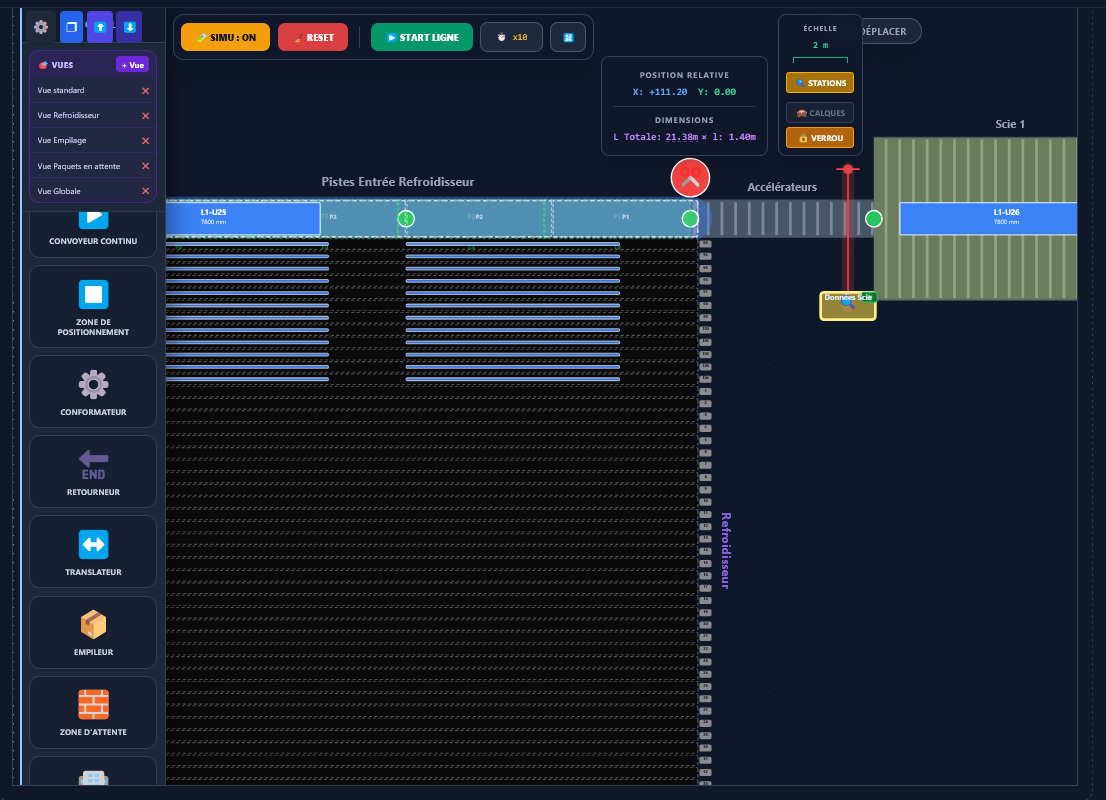
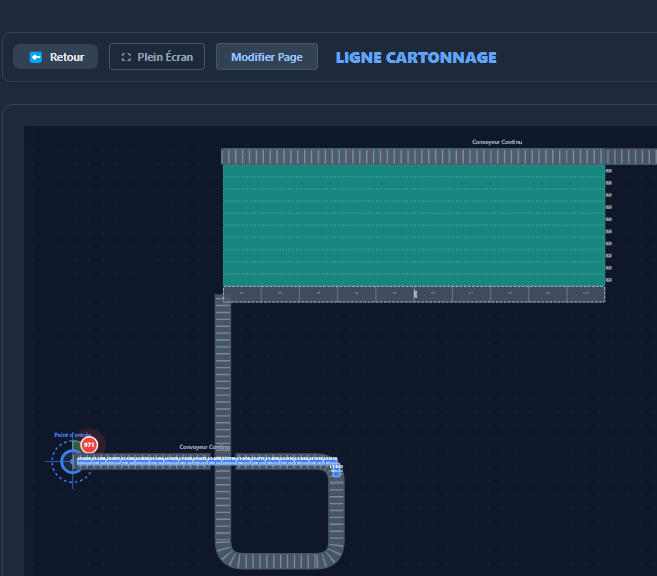
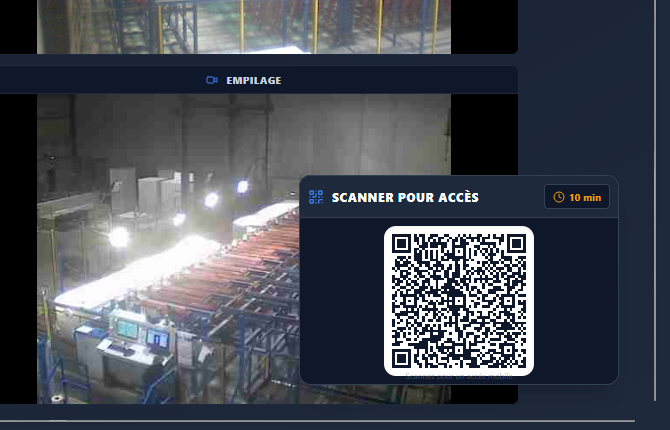
Au départ, le cas d'usage central n'était pas le grand écran de supervision en salle de contrôle. C'était le technicien de maintenance qui se déplace sur la ligne. Quand on est sous un convoyeur, dans une armoire électrique, à 50 mètres de l'écran de contrôle, pouvoir sortir son smartphone ou sa tablette de sa poche pour vérifier la valeur d'un capteur ou l'état d'un variateur, c'est un vrai gain de temps.
Les contraintes fixées dès le départ
- Zéro client lourd : tout fonctionne depuis un navigateur standard, y compris sur smartphone.
- Multi-utilisateurs simultanés : le Responsable Maintenance depuis son bureau, le Technicien depuis l'atelier.
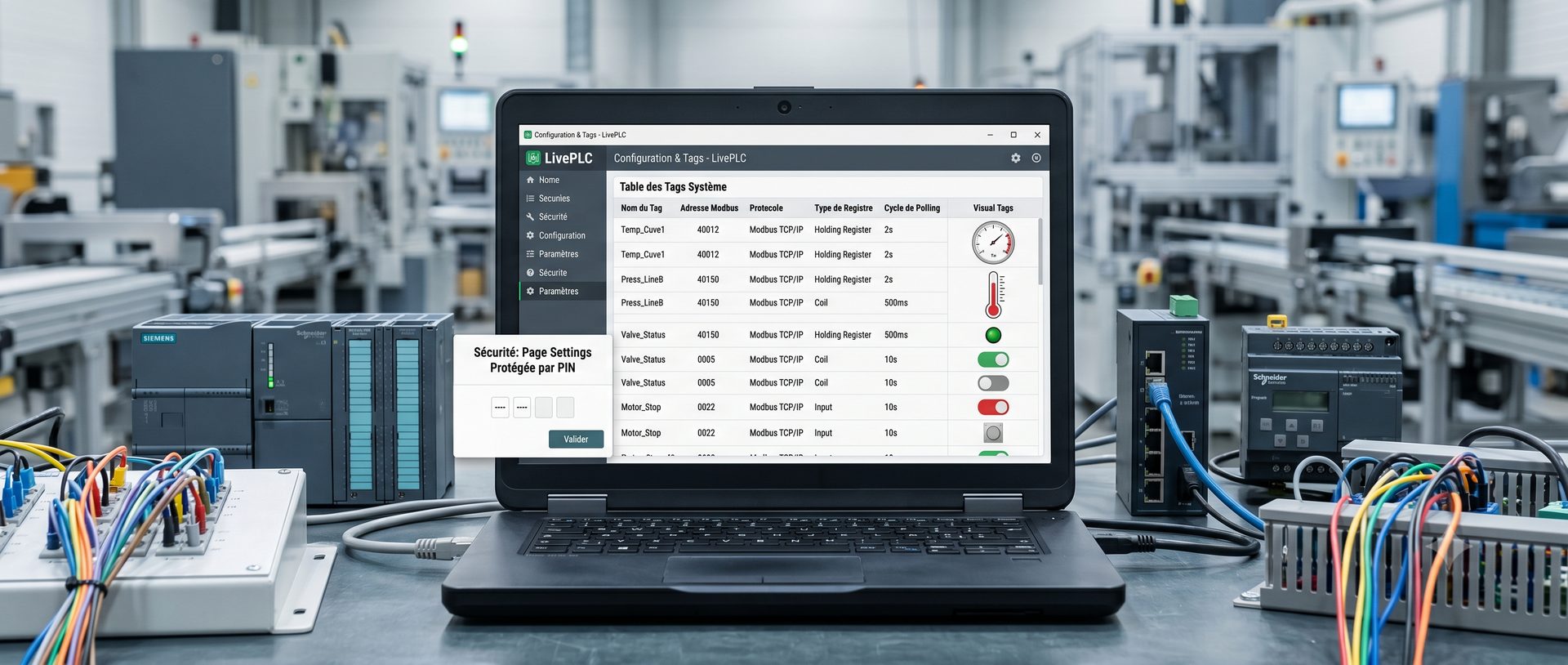
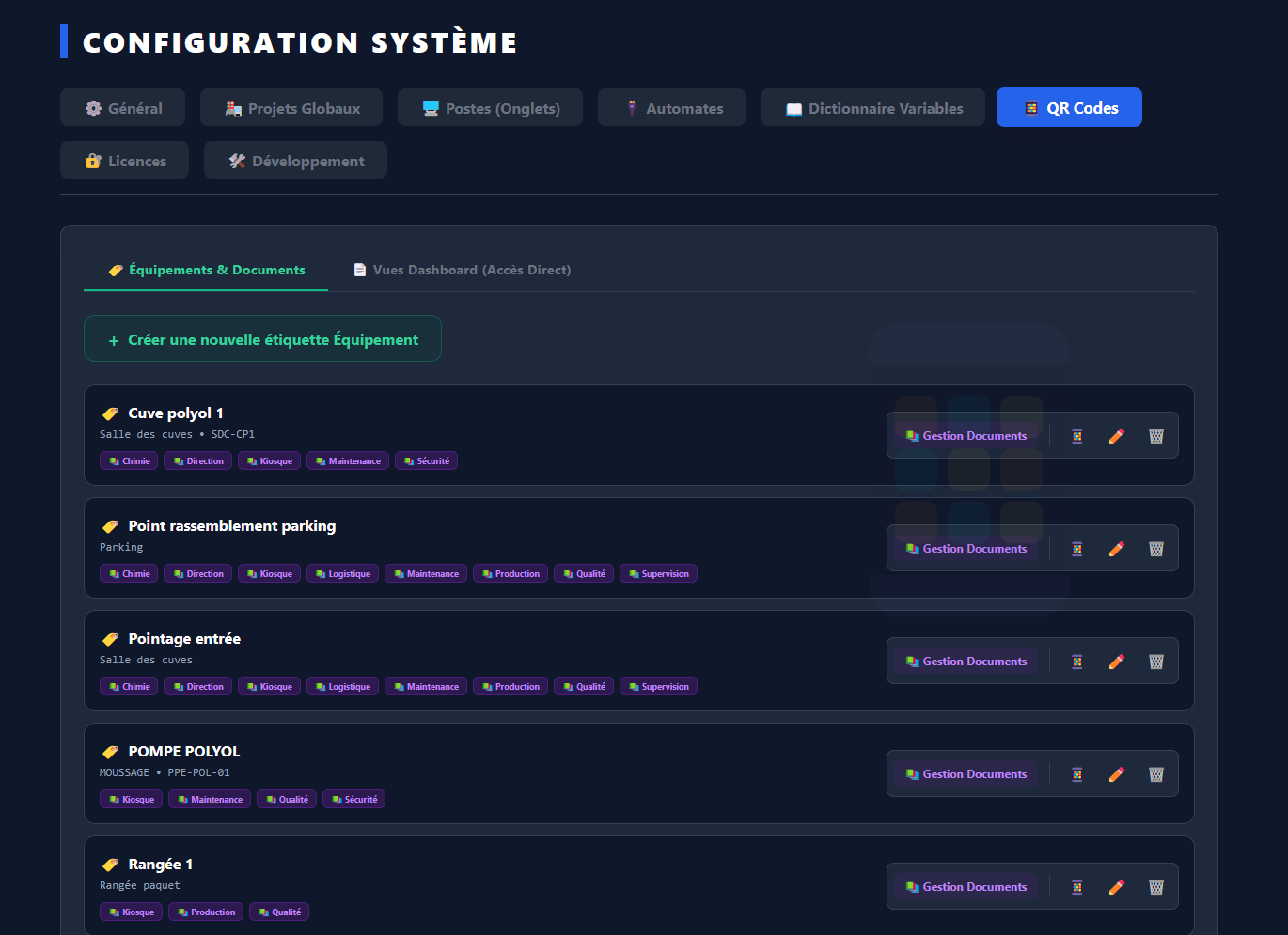
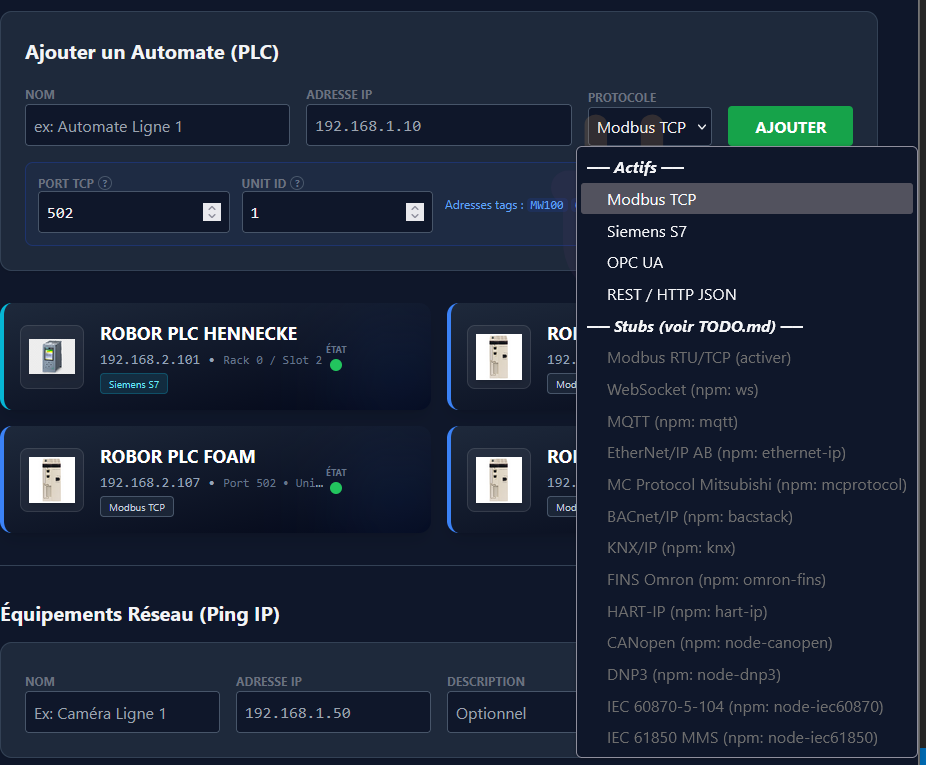
- Multi-protocoles : Modbus TCP, Siemens S7, OPC UA, les automates réels, pas seulement les modèles récents.
- Déployable sur du matériel modeste : Raspberry Pi 4, NUC, ou VM partagée pour le backend, un smartphone ou n'importe quel navigateur pour le frontend, et pourquoi pas pour la partie backend si besoin pour les installations légères.
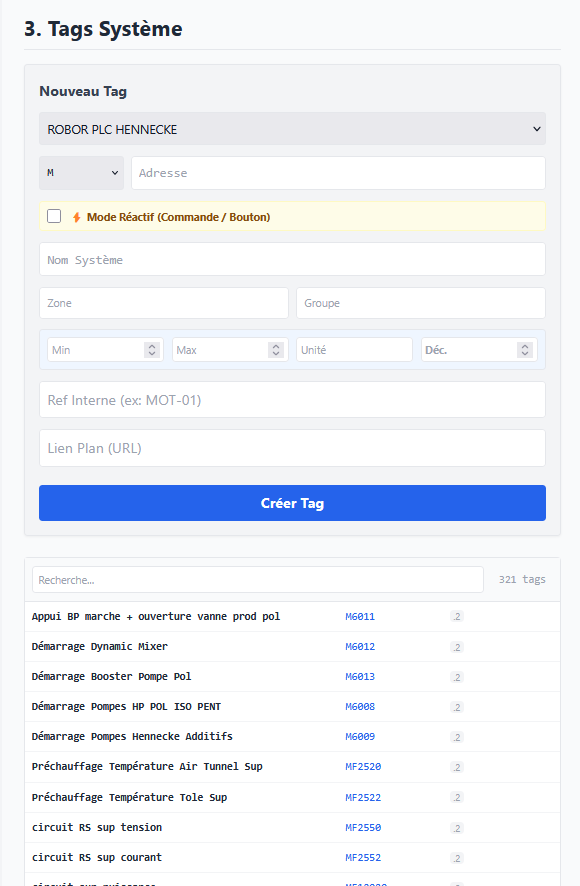
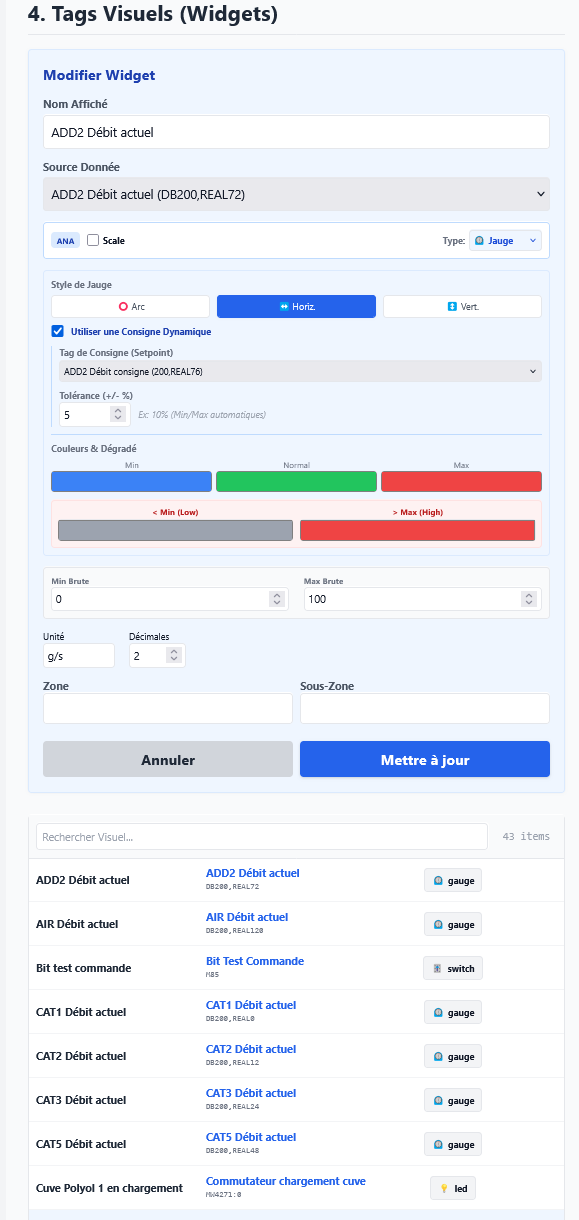
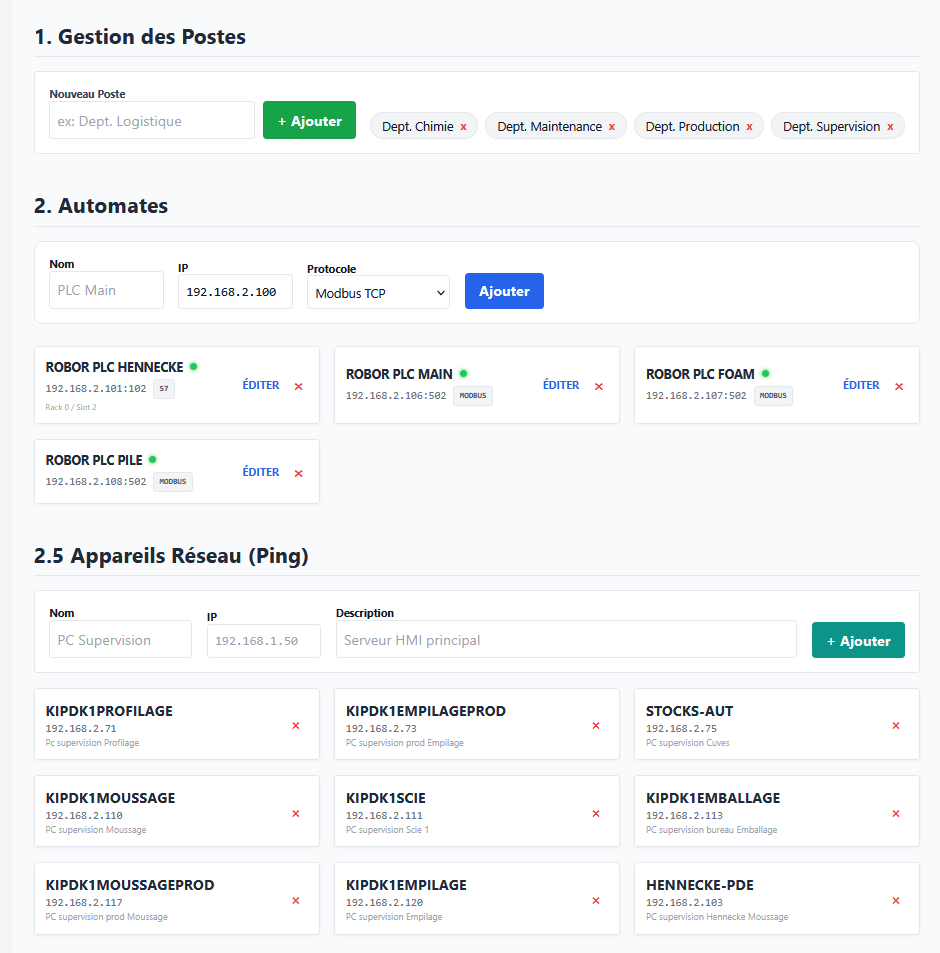
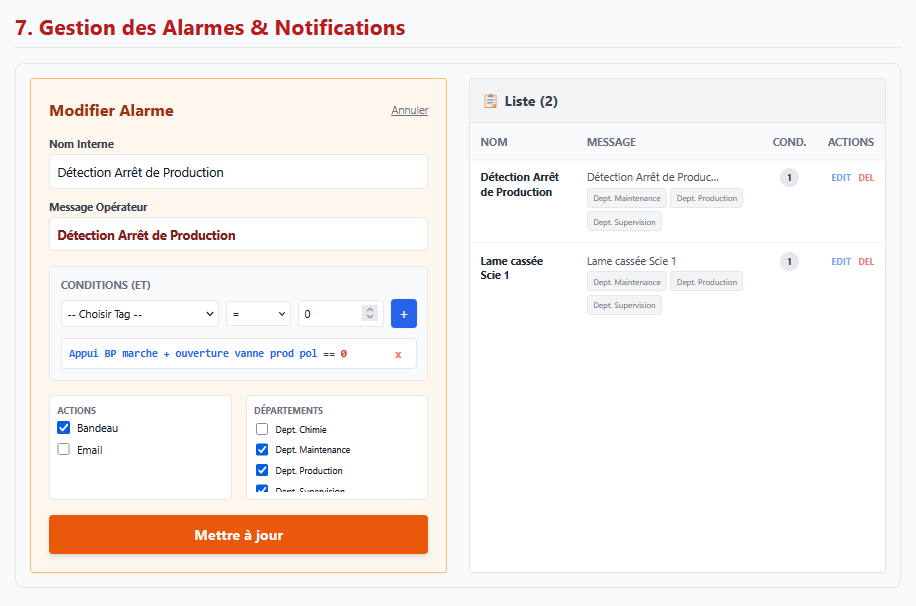
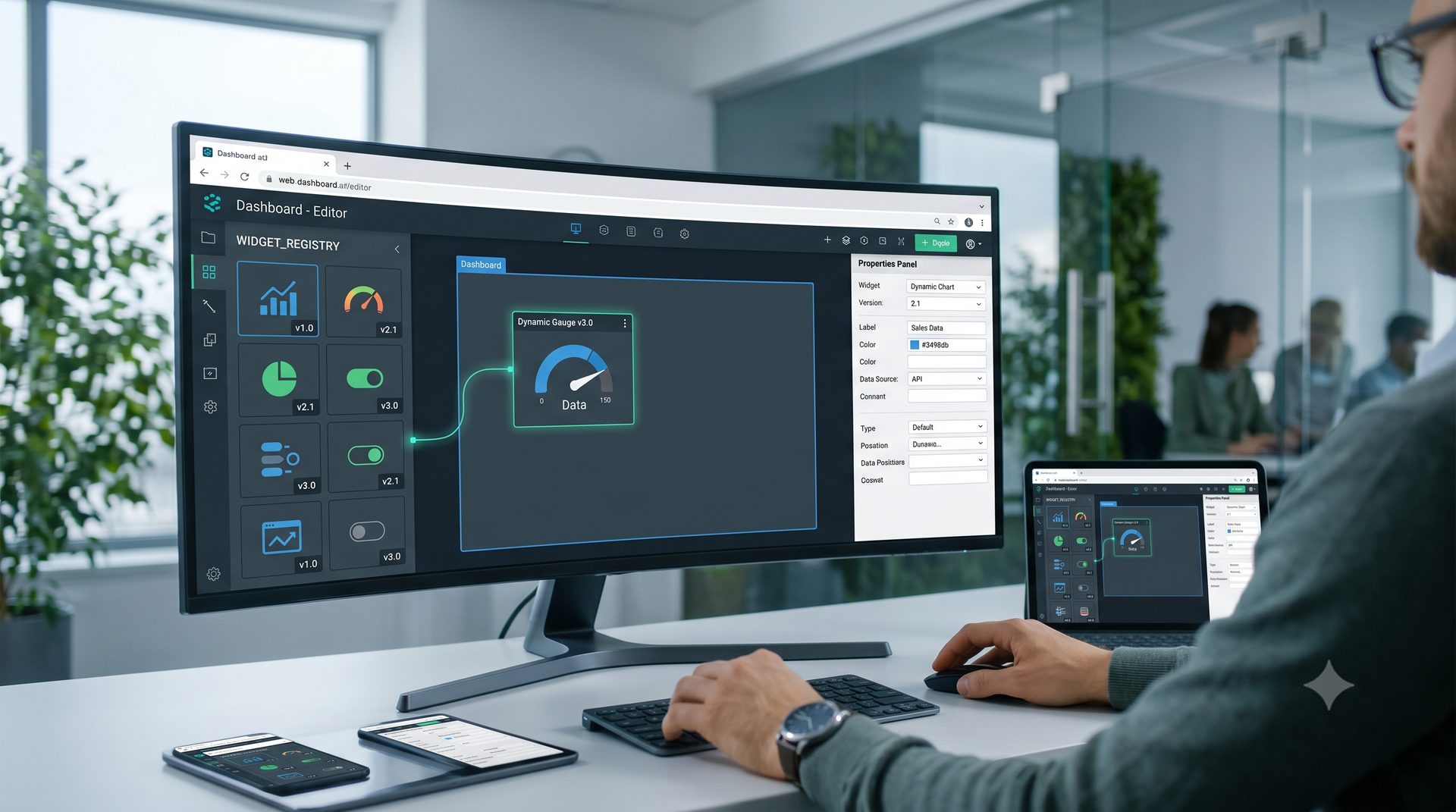
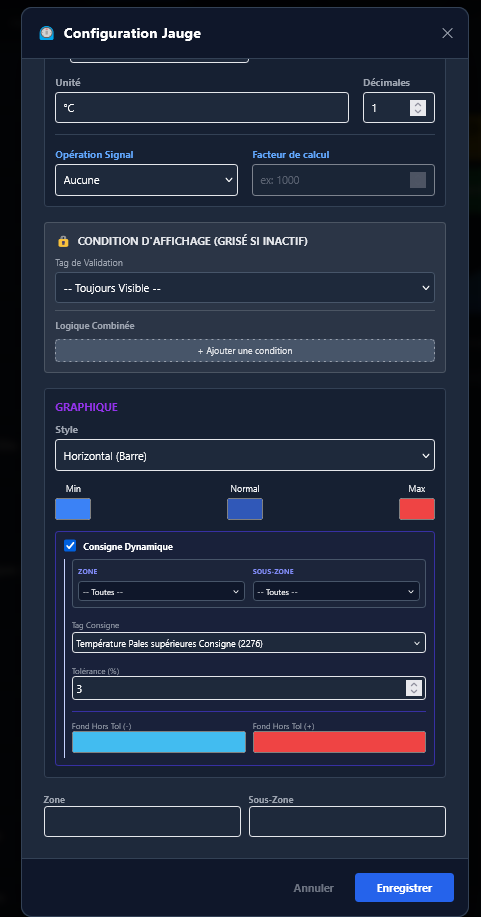
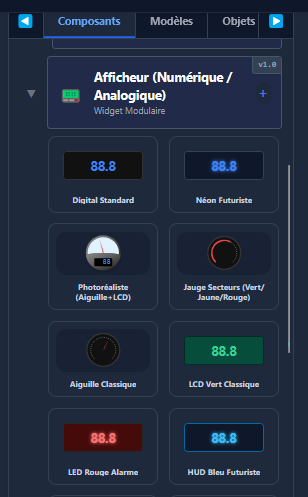
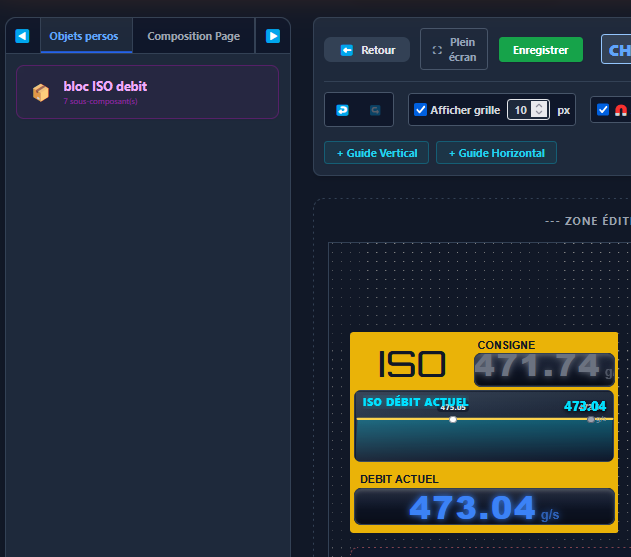
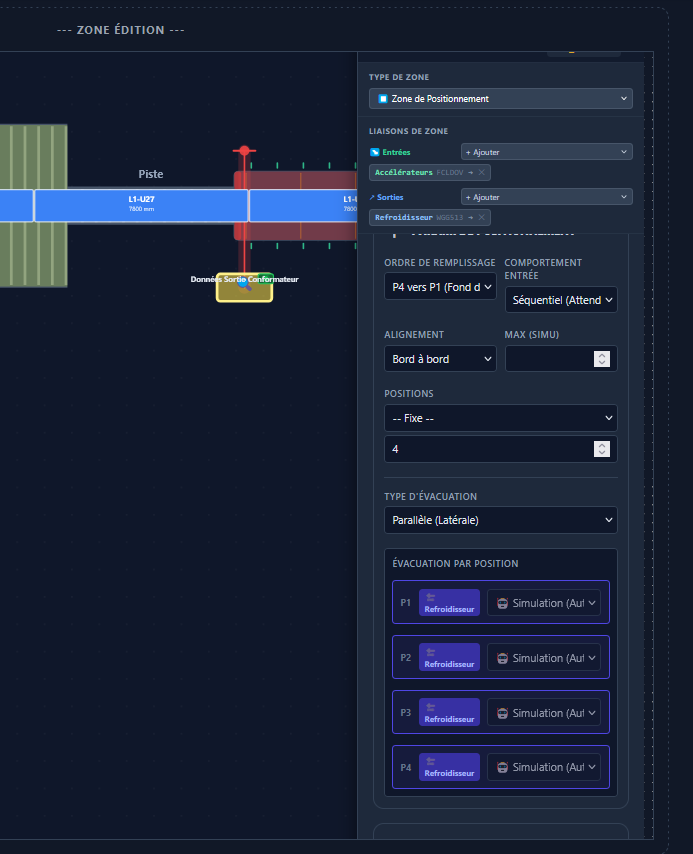
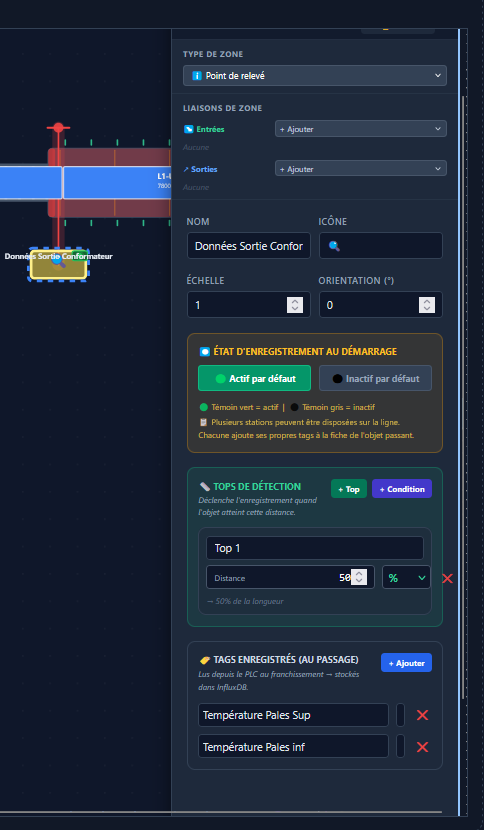
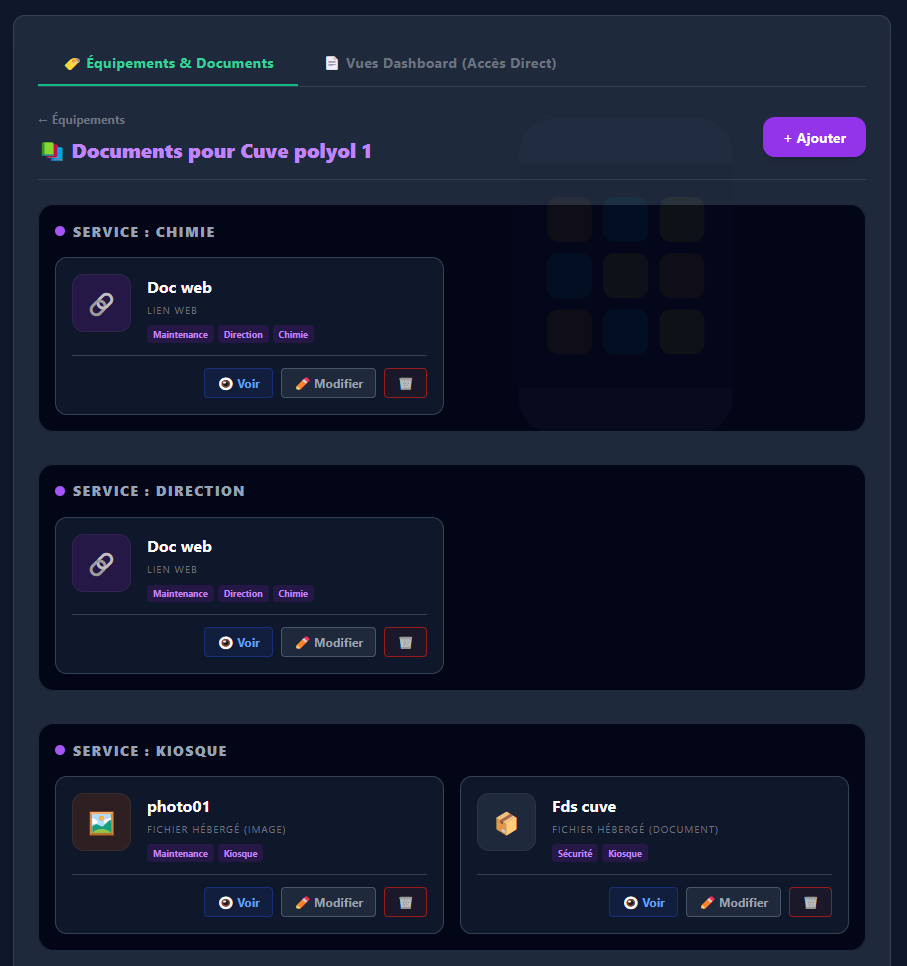
- Prise en main rapide : simplifier au maximum la création ou la modification des pages, générer et visualiser rapidement les valeurs d'un automate.
- Installation rapide : un serveur qui centralise toutes les données et un poste client équipé simplement d'un navigateur internet. En cas de dépannage d'un poste client, il n'y aura pas plus rapide.
Le choix de la stack technique
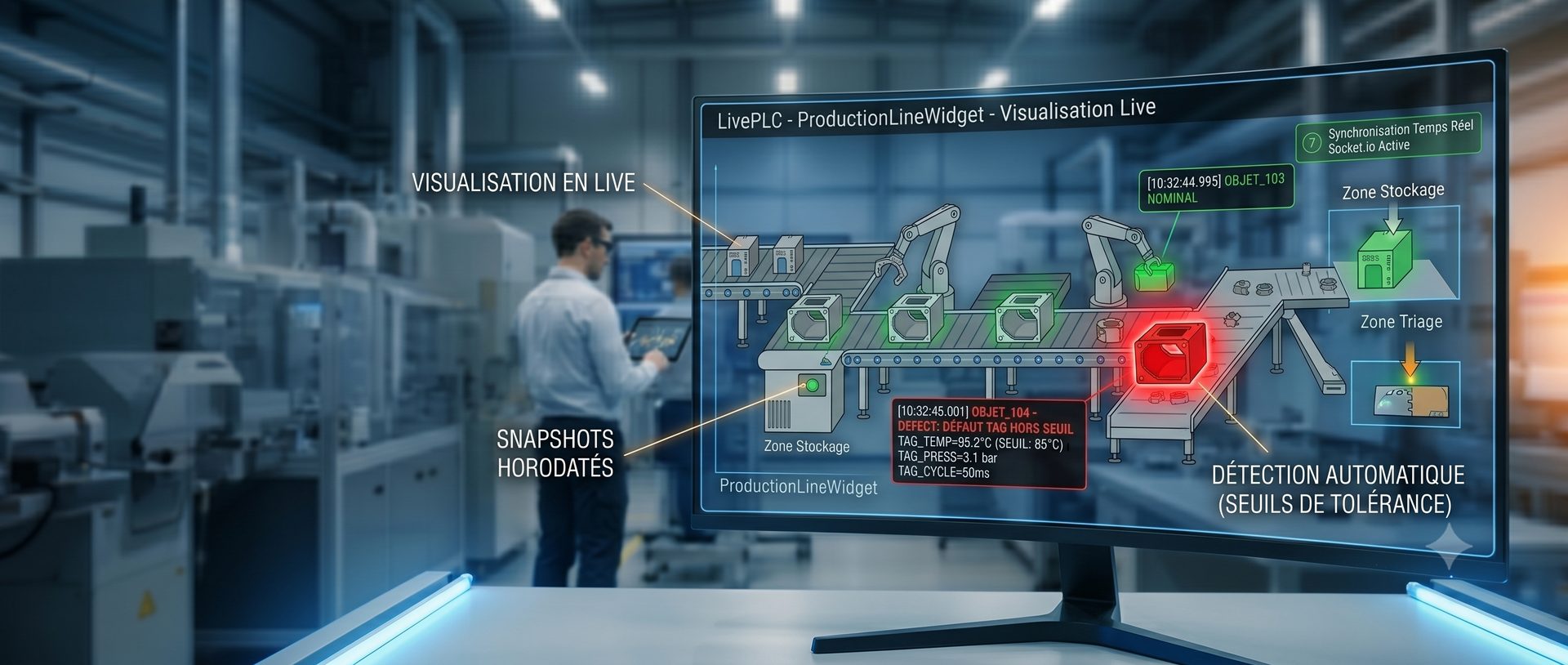
Node.js + Express pour le backend, l'écosystème npm dispose des librairies pour Modbus (jsmodbus), S7 (nodes7), OPC UA (node-opcua), et Socket.io y est chez lui pour le temps réel.
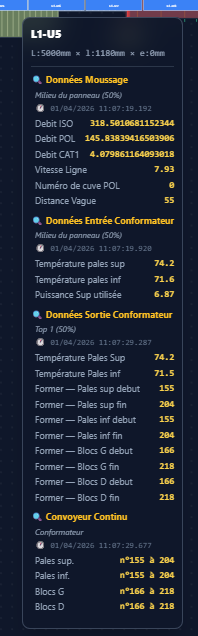
React 19 + Vite + TailwindCSS pour le frontend. React pour la gestion d'état et le système de composants. TailwindCSS parce que je n'avais pas envie de perdre du temps avec le CSS pour des dizaines de widgets différents. SQLite embarquée pour la persistance courante, la finalité étant principalement de la visualisation et du contrôle, pas de l'archivage, et plus tard InfluxDB pour l'historique des données si le besoin se fait exprimer.